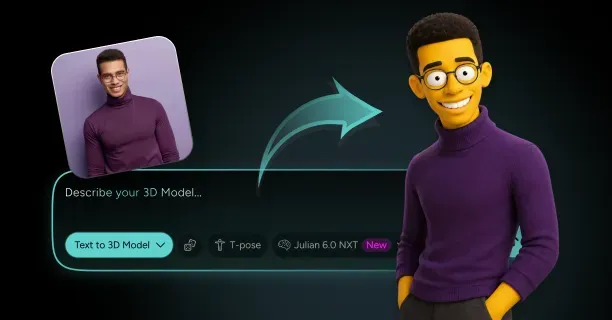



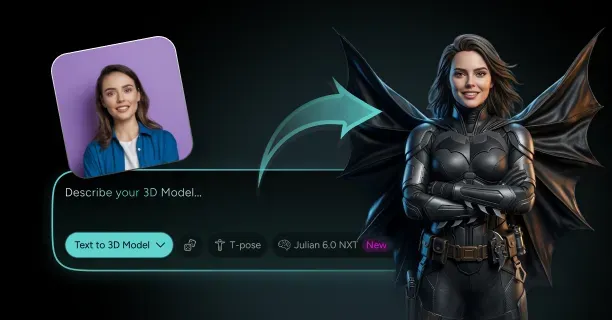


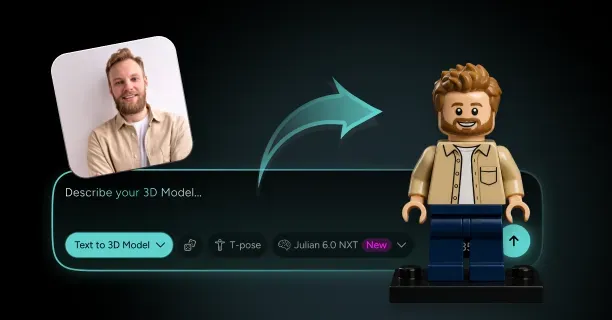
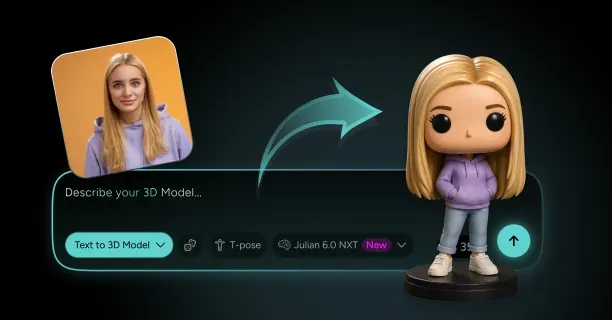
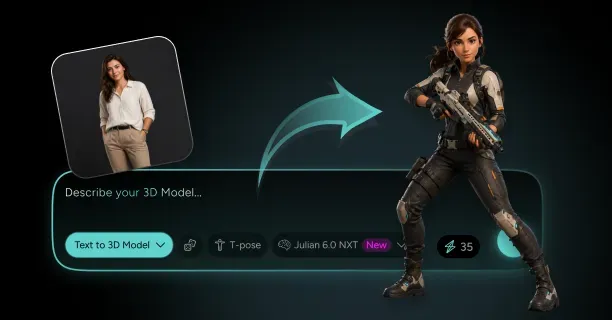
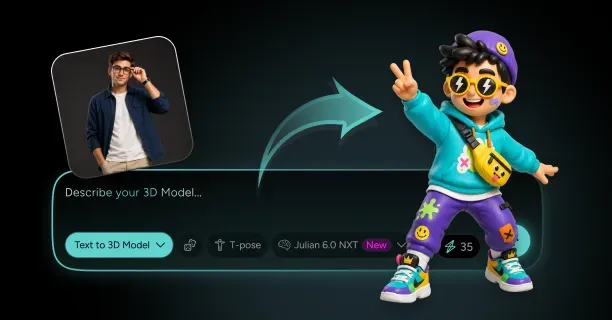

How Do You Turn a Photo of Yourself Into a 3D Character That Still Looks Like You?
To turn a photo of yourself into a 3D character that still looks like you, submit a high-resolution frontal image (minimum 1920×1080 pixels) to AI-powered reconstruction platforms that use deep learning models to extract your facial features and generate a 3D polygonal mesh with texture mapping. The reconstruction process employs computational analysis to infer depth information, contours, and photometric data from your single photograph, transforming flat pixel data into volumetric geometry while maintaining your recognizable likeness.
Monocular Reconstruction Techniques
Single-image 3D reconstruction transforms photos into avatars through AI-driven methods that employ deep learning models trained on extensive human face datasets. Neural networks infer three-dimensional structure from single input images by identifying geometric patterns the networks learned from diverse facial structures during training. Upload one photograph: that is all you need for modern AI-based methods, and neural networks automatically infer the missing depth data. Threedium's Julian NXT technology processes your uploaded image through specialized neural architectures that map 2D pixel coordinates to 3D spatial positions, creating a complete head model from a single viewpoint.
Parametric Morphable Models (3DMMs) align a deformable 3D face model to your photo by optimizing statistical parameters that control facial shape variations. This fitting process ensures the system corresponds to your specific features while maintaining anatomically realistic proportions. The 3DMM approach utilizes a database of scanned faces that form a mathematical space of possible face shapes, optimizing parameters to match visible landmarks in your photograph:
- Eye corners
- Nose tip
- Jawline contours
This fitting process preserves your distinctive facial structure and reduces visual differences between the 3D model's appearance and your actual photograph.
Generative Adversarial Networks (GANs) synthesize novel 3D views to infer facial geometry by training two competing networks: a generator that creates 3D face candidates and a discriminator that evaluates how realistic these candidates appear against actual human faces. The generator learns to produce 3D meshes that fool the discriminator into classifying them as real, developing an internal understanding of facial geometry that enables accurate reconstruction from limited input. Upload your photo and the trained GAN generator extracts facial features, producing a 3D mesh that matches your appearance while extrapolating hidden regions: like the back of your head, using patterns the generator learned from its training dataset.
Neural Radiance Fields (NeRFs) optimize a continuous volumetric representation from images by encoding the 3D scene as a neural network that maps spatial coordinates and viewing directions to color and density values. In single-image face reconstruction, NeRF-based approaches train on multi-view face datasets and fine-tune for your specific photograph by optimizing the network to reconstruct your facial appearance from the given viewpoint. This volumetric representation captures fine details like skin texture variations, subtle facial asymmetries, and complex lighting interactions that simpler mesh-based methods fail to capture, resulting in photorealistic 3D characters with exceptional visual fidelity.
Facial Feature Analysis and Geometry Extraction
Deep learning models process and extract facial features from your 2D image by detecting and pinpointing key anatomical landmarks: ranging from 68 to 468 distinct points depending on model sophistication, defining spatial relationships between eyes, nose, mouth, cheekbones, and jaw structure. This landmark detection provides the geometric skeleton that guides mesh deformation, ensuring your 3D character's face maintains the same proportional relationships as your photograph. Threedium's reconstruction pipeline detects and localizes these landmarks with sub-pixel accuracy, quantifying distances between features:
| Measurement Type | Description |
|---|---|
| Interpupillary distance | Space between eye centers |
| Nose width | Horizontal span of nostrils |
| Mouth height | Vertical lip dimension |
This calibrates the 3D model's dimensions precisely according to your facial metrics.
Vertex positioning algorithms generate a 3D mesh by positioning thousands of 3D points in space to form the character's surface geometry. Typical game-ready character heads contain 15,000 to 20,000 polygons optimized for real-time rendering. Each vertex receives coordinates (x, y, z) calculated from the depth estimation neural network's output, estimating how far each facial region extends from the camera plane based on learned correlations between 2D appearance cues and 3D structure. The mesh topology: how vertices, edges, and faces are arranged and connected, follows a standardized facial layout that supports animation, placing edge loops around eyes, mouth, and other deformable regions where your character needs to express emotions or speak.
Texture mapping and projection transfer colors and surface details from your photograph onto the 3D model's surface by unwrapping the mesh into a 2D texture space (UV unwrapping) and sampling pixel colors from your image at corresponding positions. This process creates a texture map: typically at 1024×1024 pixel resolution, that stores skin tone variations, freckles, wrinkles, and other photographic details as a flat image wrapping around the 3D geometry. Texture projection algorithms account for perspective distortion in your original photo, making sure the final texture applies uniformly across the 3D surface without stretching or compression artifacts.
Depth Inference and Surface Reconstruction
AI-powered avatar creation systems infer depth information from your single photograph by training on datasets where both 2D images and corresponding 3D scans exist, learning correlations between visual cues:
- Shading
- Occlusion boundaries
- Feature sizes
And actual depth values. This inference positions your nose forward from your face plane, sets your eyes into appropriate orbital depth, and curves your cheeks according to their apparent roundness. Neural networks encode these depth relationships as millions of learned parameters that activate in response to specific pixel patterns, producing a depth map: a grayscale image where brightness represents distance from the camera, that guides 3D surface placement.
The reconstruction algorithm converts this depth map into explicit 3D geometry by treating each pixel as a potential surface point, calculating its 3D coordinates using the estimated depth and the pixel's 2D position, then connecting neighboring points into triangular faces that form the mesh surface. A complete head model emerges even though your photo shows only the front view because the system extrapolates hidden regions: sides and back of head, using statistical priors learned from thousands of complete head scans in its training data. This extrapolation maintains realistic anatomy, making sure your 3D character's head has realistic curvature, ear placement, and back-of-head shape, even when those regions never appeared in your input photograph.
Volumetric representation methods divide the 3D space around your head into a grid of tiny 3D pixels (voxels), assigning each voxel an opacity value that indicates whether it contains solid facial tissue or empty air, creating a continuous field that defines your face's shape. This approach excels at capturing fine geometric details like:
- Individual hair strands
- Subtle skin wrinkles
- Complex surface irregularities
Because it represents geometry at a much higher resolution than traditional polygon meshes. Neural networks learn this volumetric representation by processing your photo through convolutional layers that predict occupancy probabilities for each voxel position, building up a complete 3D volume that, when rendered, reproduces your facial appearance from any viewing angle.
Automated Generation Versus Manual Refinement
Automated systems create a base mesh within seconds to minutes by executing the trained neural network's inference process on your uploaded photo, producing a complete 3D character without human intervention.
Threedium's Julian NXT technology processes your image through multiple neural network stages:
- Landmark detection
- Depth estimation
- Mesh generation
- Texture projection
Resulting in a rigged, textured 3D character ready for immediate use in games, virtual environments, or animation projects. This automation eliminates weeks of manual labor that were traditionally required for character creation, making personalized 3D avatars accessible to anyone with a smartphone camera rather than requiring professional 3D artists and expensive scanning equipment.
Manual 3D sculpting offers the highest level of artistic control for creators who need absolute accuracy or stylistic interpretation beyond what automated systems provide. An artist uses the photo as a reference for sculpting, working in digital sculpting software to manually place and shape millions of polygons, capturing subtle asymmetries, expression lines, and character-defining details that generic AI models might average away. This manual method requires 20 to 40 hours of skilled artist time to achieve photorealistic likeness, making it economically viable only for high-value projects like film digital doubles or premium game characters where perfect accuracy justifies the cost.
Hybrid approaches combine automated generation with manual refinement, using AI to handle the time-consuming initial geometry creation while reserving human expertise for final accuracy adjustments and artistic polish. You benefit from this hybrid workflow when using Threedium's platform because the automated generation provides an immediately usable character while still allowing export to professional 3D software for further customization if your project demands it.
Preserving Facial Likeness Through Feature Matching
Your 3D character maintains recognizable likeness through precise measurement and replication of distinctive facial metrics: the ratios and distances between features that define your face as uniquely identifiable. The reconstruction system quantifies:
| Facial Metric | Description |
|---|---|
| Interpupillary distance | Space between your eye centers |
| Philtrum length | Vertical groove between nose and upper lip |
| Zygomatic width | Cheekbone span |
| Additional dimensions | Dozens of other anthropometric measurements |
From your photo, then adjusts the 3D model to match these measurements within sub-millimeter accuracy. This dimensional fidelity makes sure that someone viewing your 3D character perceives the same facial proportions they would recognize in your photograph, maintaining identity across the 2D-to-3D transformation.
Facial asymmetries: the subtle left-right differences present in every human face, get special attention during reconstruction because these imperfections contribute significantly to recognizable likeness. The AI system detects that your left eye sits slightly higher than your right, one cheek curves more prominently, or your smile pulls asymmetrically, then reproduces these variations in the 3D geometry rather than averaging them into perfect symmetry. You see this asymmetry preservation when your 3D character displays the same slightly crooked smile or uneven eyebrow position visible in your reference photo, details that generic symmetric models would erase but that prove important for authentic personal representation.
Skin texture details: freckles, moles, fine wrinkles, and color variations, transfer from your photograph to the 3D model's texture map through high-resolution sampling that captures pixel-level detail from your image. The texture projection algorithm identifies these features' locations in your photo, maps them to corresponding positions on the 3D mesh's UV layout, and preserves their appearance in the final texture, making sure your virtual character displays the same distinctive marks as your real face. This photographic texture fidelity creates immediate recognition even when viewing the 3D character from angles not present in the original photo, as familiar skin details remain consistent across the model's surface.
Technical Constraints and Input Requirements
Optimize reconstruction accuracy by providing a high-resolution frontal photograph with even lighting, neutral expression, and clear visibility of facial features from hairline to chin. The AI models perform best when your photo satisfies specific technical criteria:
- Minimum 1920×1080 pixel resolution to capture fine facial details
- Frontal view (face directly toward camera) to minimize perspective distortion
- Diffuse lighting that avoids harsh shadows obscuring facial contours
Threedium's platform processes standard smartphone photos that meet these criteria, correcting minor lighting irregularities, slight head rotations, or resolution limitations before feeding the image to the reconstruction neural network.
Provide three photos: frontal, left-profile, and right-profile images, to improve accuracy, especially for capturing the sides of the head and reducing guesswork in hidden regions. Multi-view stereo reconstruction algorithms triangulate corresponding points across photos to calculate precise 3D positions, producing geometry more accurate than single-image methods. This approach reduces reliance on statistical priors for extrapolating hidden surfaces and measures actual geometry from multiple viewpoints, though it requires careful photo capture with consistent lighting and camera settings across all views.
The reconstruction quality depends heavily on the training data diversity the AI model learned from, with systems trained on datasets representing wide demographic variation producing more accurate results across different ethnicities, ages, and facial structures.
Neural networks trained predominantly on one demographic group may struggle to accurately reconstruct faces from underrepresented groups, potentially averaging features toward the training set's dominant characteristics rather than preserving your unique appearance. Threedium's Julian NXT technology trains on diverse international face datasets to minimize this bias, making sure your 3D character maintains authentic likeness regardless of your ethnic background, age, or distinctive facial features.
Real-Time Processing and Output Formats
Modern AI-sculpting workflows complete the entire photo-to-avatar pipeline in real-time or near-real-time, with processing times ranging from 15 seconds to 3 minutes depending on output quality settings and computational resources. Upload your photo to the tool above and obtain a complete rigged 3D character: including mesh geometry, UV-mapped texture, and skeletal rig for animation, without waiting for lengthy processing queues or manual artist intervention. This speed results from fine-tuned neural network architectures executing inference on GPU hardware, performing billions of mathematical operations per second to transform your 2D pixels into 3D geometry faster than traditional photogrammetry pipelines.
The generated 3D character exports in industry-standard formats (FBX, GLB, OBJ) that work with:
- Game engines
- 3D animation software
- Virtual reality platforms
- Web-based 3D viewers
Making sure your personalized avatar integrates seamlessly into your target application. You receive a game-ready asset with clean topology suitable for real-time rendering, an optimized polygon count that balances visual detail against performance needs, and properly configured texture maps (diffuse color, normal maps for surface detail, and optionally specular or roughness maps for material properties). This production-ready output eliminates technical conversion work typically required when moving 3D assets between different software platforms, allowing immediate deployment of your character in Unity, Unreal Engine, or web-based Three.js applications.
Threedium's reconstruction model outputs characters with standardized skeletal rigs following humanoid animation conventions, placing joints at anatomically correct positions (neck, jaw, eyes) and configuring bone hierarchies that support industry-standard animation retargeting. You can animate your 3D character using:
- Motion capture data
- Keyframe animation
- Procedural animation systems
Without manual rigging work because the automated system positions and weights the skeleton during generation. This animation-ready output proves essential for applications requiring your character to move, speak, or express emotions: virtual meetings, gaming avatars, or animated content, where static geometry alone isn't enough.
What Kind of Photo, Pose, and Outfit Create the Best 3D Character of Yourself?
Photo Quality Requirements
The best 3D character creation requires a high-resolution photograph with minimum 12 megapixels, proper lighting, and specific technical settings to ensure accurate reconstruction. Configure your camera's ISO setting to its lowest native value: typically ISO 100 or ISO 200 to minimize digital noise artifacts that degrade texture data quality during 3D reconstruction.
Shoot in RAW format to preserve maximum color depth (14-bit or 16-bit) and dynamic range, which reconstruction algorithms require for accurate material interpretation.
Key Distance and Focal Length Requirements:
- Position yourself at a distance of 4 to 6 feet from the camera lens
- Utilize a camera focal length between 50 millimeters and 85 millimeters
- Position the camera at the subject's eye level
These specifications help to:
- Maintain proper perspective
- Avoid wide-angle distortion
- Prevent telephoto compression artifacts
- Minimize barrel distortion and pincushion distortion
Frame the photograph to include the subject's entire head with 20% to 30% additional space surrounding the head's outline, providing sufficient boundary data for accurate edge detection during 3D reconstruction. This additional framing space provides reconstruction algorithms with sufficient boundary data to perform accurate edge detection and precisely define the subject's silhouette in the 3D model.
Maintain sharp focus across all of the subject's facial features by either using single-point autofocus centered on the subject's eyes or by manually focusing on the plane of the subject's face, ensuring that all facial details remain crisp for accurate 3D reconstruction.
Lighting Configuration
Achieve optimal 3D reconstruction results by implementing even and diffuse lighting that eliminates harsh shadows from the subject's facial topology, preventing reconstruction algorithms from misinterpreting shadow boundaries as geometric features.
Optimal Lighting Setup:
| Light Position | Angle | Height | Purpose |
|---|---|---|---|
| Light Source 1 | 45-degree angle | Slightly above eye level | Balanced illumination |
| Light Source 2 | 45-degree angle (opposite side) | Slightly above eye level | Shadow elimination |
Avoid direct sunlight or single-point artificial lights that create high-contrast shadows, as reconstruction algorithms will misinterpret these shadow patterns as permanent geometric features or texture variations.
White Balance Configuration:
- 5500 Kelvin for daylight conditions
- 3200 Kelvin for tungsten bulb illumination
- Utilize a gray card reference to establish accurate color calibration
Color casts resulting from incorrect white balance settings introduce false hue information into texture maps, necessitating time-consuming manual color correction during the post-processing stage and reducing overall workflow efficiency.
Avoid low-light conditions below 500 lux, as insufficient illumination forces the camera to increase ISO sensitivity, introducing grain patterns and digital noise artifacts that degrade texture quality and compromise the fidelity of 3D surface maps.
Select a neutral, uncluttered background in solid gray, white, or light blue to facilitate subject isolation and enable edge-detection algorithms to accurately identify the outer boundary separating the subject's silhouette from the surrounding environment during automated segmentation.
Facial Pose Standards
Provide reconstruction algorithms with the most accurate base geometry by maintaining a neutral facial expression characterized by:
- Subject's mouth closed
- Eyes open
- Gaze directed forward at the camera lens
This establishes the foundational topology for accurate 3D facial modeling. Neutral expressions preserve the subject's rest position topology which serves as the essential foundation for facial rigging systems and blend shape generation required for realistic 3D character animation.
Critical Positioning Requirements:
- Center the subject's head within the frame
- Face oriented perpendicular to the camera sensor plane
- Ensure bilateral symmetry along the vertical midline
- Position shoulders square to the camera
Avoid tilting the subject's head left or right, and prevent rotating the face away from the camera, as these angular deviations create foreshortening on one side of the face and introduce asymmetric reconstruction errors.
Maintain the subject's chin level with the horizon line to prevent upward or downward head angles that distort facial proportions. Reconstruction algorithms incorrectly interpret perspective distortion as actual geometric variation in facial structure; consequently:
- A downward-tilted head produces an artificially elongated forehead
- An upward-tilted head compresses vertical facial dimensions
Clothing and Styling
Reduce geometric complexity in 3D reconstruction by selecting solid-colored clothing without patterns, logos, text, or reflective materials. These elements introduce unnecessary texture detail and increase processing overhead without contributing to facial likeness accuracy.
Optimal Clothing Selection Guidelines:
| Skin Tone | Recommended Clothing Color | Reason |
|---|---|---|
| Light skin tones | Dark clothing | Clear visual boundaries |
| Dark skin tones | Light clothing | Enhanced contrast |
Avoid These Materials:
- White or black clothing (causes highlight or shadow clipping)
- Glossy or metallic materials
- Reflective surfaces
Select matte fabrics instead of glossy or metallic materials, as reflective surfaces create specular highlights that reconstruction algorithms misinterpret as permanent surface geometry rather than transient lighting effects.
Accessories to Remove:
- Jewelry
- Glasses
- Hats
- Scarves
- Earrings
- Necklaces
- Piercings
These elements introduce false topology into the reconstructed mesh, creating geometric artifacts that do not represent actual facial structure.
Hair Styling Requirements:
Style the subject's hair to reveal the complete facial outline and forehead, pulling long hair back or tucking it behind the ears to expose the full perimeter of the face.
This ensures that reconstruction algorithms capture the entire facial boundary without obstruction from overlapping hair strands. Loose hair strands crossing the subject's face create semi-transparent elements that disrupt reconstruction algorithm processing, producing floating geometry artifacts or holes in the final mesh.
Avoid complex hairstyles with:
- Volume extending beyond head silhouette
- Layering that challenges algorithm precision
- Elaborate styles that increase processing time
Why Does Threedium Create More Accurate 3D Versions of Real People From a Single Photo?
Threedium creates more accurate 3D versions of real people from a single photo because its proprietary Julian NXT reconstruction engine integrates advanced computer vision algorithms with generative neural networks trained on over one million high-resolution 3D human scans. When a user uploads a single photograph to Threedium's reconstruction platform, the Julian NXT AI system extracts facial and body landmarks, computes three-dimensional geometry from the user's 2D pixel data, and generates a high-quality polygonal mesh that preserves the individual's anatomical features, body proportions, and unique physical characteristics. The reconstruction accuracy stems from the massive training dataset that enables the AI to learn complex spatial relationships between 2D photographic images and 3D human anatomical structures, allowing the system to generate character models that maintain high fidelity to the user's source photograph without requiring specialized 3D scanning equipment or multiple calibrated camera angles.
Training Dataset Scale
Threedium's Julian NXT AI system trains on a comprehensive dataset containing over one million high-resolution 3D human scans, providing the neural networks with foundational anatomical knowledge required for accurate single-photograph 3D character model generation. This comprehensive training collection provides the generative neural networks with exposure to diverse human anatomical variations, including:
- Varied facial structures
- Multiple body types
- Different proportions across demographic categories
- Various age groups
- Ethnic backgrounds
- Physical characteristic ranges
The dataset scale enables the AI system to recognize subtle variations in human anatomical form and accurately infer three-dimensional geometric structure by analyzing lighting patterns, shadow information, and perspective cues present in the user's input photograph. Training on such an extensive dataset collection enables the reconstruction system to accurately handle edge cases and unusual anatomical features that smaller training datasets fail to reconstruct properly, ensuring the individual's unique physical characteristics transfer correctly into the generated 3D character model rather than being averaged out through statistical normalization or geometrically distorted.
The training dataset contains paired examples consisting of:
- 2D photographs
- Corresponding high-resolution 3D scan counterparts
This training approach enables the generative neural networks to accurately transform flat photographic images into volumetric three-dimensional representations with consistent reconstruction accuracy.
Landmark Detection Precision
The reconstruction process leverages advanced computer vision algorithms integrated within Threedium's Photo-to-Avatar Engine that detect key facial and body landmarks with sub-pixel precision accuracy, establishing anatomical anchor points that guide the subsequent 3D polygonal mesh construction process.
| Anatomical Features | Detection Points |
|---|---|
| Eye corners | Precise spatial coordinates |
| Nose tip | Sub-pixel accuracy |
| Mouth edges | Contour mapping |
| Jawline contours | Edge definition |
| Ear positions | 3D positioning |
| Body joint locations | Skeletal framework |
The precision with which the detection system locates anatomical landmarks directly influences the final 3D character model's accuracy because these detected points function as ground truth reference coordinates that constrain the generative reconstruction process and prevent the AI from producing anatomically impossible geometric results.
Threedium's landmark detection system analyzes the user's uploaded photograph through specialized convolutional neural networks optimized specifically for facial keypoint localization, achieving positional detection accuracy within 0.5 pixels on standard resolution photographic images.
Each detected landmark contains:
- Three-dimensional spatial coordinates
- Associated confidence scores
- Guidance for subsequent reconstruction processing steps
Generative Model Architecture
The generative neural network models construct a three-dimensional polygonal mesh from extracted 2D photographic data by predicting depth values and volumetric spatial information for each detected anatomical landmark and interpolating surface geometry between established anchor points.
The generative model architecture employs deep neural networks trained to transform 2D facial pattern features into corresponding 3D spatial coordinates through supervised learning on paired training datasets containing matched 2D photographs and their corresponding high-resolution 3D scan counterparts.
When users upload their photograph to Threedium's reconstruction tool, the generative neural network models process:
- Detected landmark coordinates
- Surrounding pixel intensity data
- Z-axis depth value computations
- Three-dimensional volumetric character representation
This reconstruction process generates vertices, edges, and polygonal faces that collectively form the three-dimensional mesh structure, ensuring the resulting 3D character model preserves anatomical proportions and facial features visible in the user's original source photograph.
The generative model architecture implements encoder-decoder neural network structures with skip connections that retain fine-grained facial detail throughout the 2D-to-3D geometric transformation process, preventing information degradation that commonly occurs in simpler sequential processing pipeline architectures.
Single-Photo Reconstruction Capability
Users provide only a single standard 2D photograph as input, eliminating the requirement for:
- Specialized 3D scanning equipment
- Controlled studio lighting environments
- Multiple calibrated camera angles
- Traditional photogrammetry-based 3D reconstruction methods
Threedium's AI-driven reconstruction approach processes the user's uploaded photograph to extract sufficient visual information for generating a complete 3D character model, leveraging neural network training on over one million 3D human scans to accurately infer hidden and non-visible geometric structures based on visible facial and body cues.
The AI system predicts lateral profile shape, posterior head geometry, and three-dimensional facial feature contours by identifying visible pattern features that statistically correlate with specific 3D anatomical forms learned from the training dataset, even when only the frontal view of the face is captured in the photograph.
The reconstruction system leverages learned knowledge about:
- Human facial symmetry principles
- Anatomical structural constraints
- Synthesis of regions not directly visible
- Anatomically realistic three-dimensional geometry
Threedium's single-photo reconstruction technology reduces total data acquisition time from hours to seconds compared to traditional multi-view photogrammetry workflows that require capturing and processing dozens of calibrated photographs from multiple camera positions.
Mesh Quality and Topology
Threedium's AI reconstruction pipeline generates three-dimensional character meshes with clean topological structure that follows natural edge flow patterns around facial features and body contours, producing character models that:
- Deform realistically during animation rigging
- Render efficiently in real-time graphics engines
- Generate quad-based polygonal topology
- Maintain uniformly distributed vertices
The mesh construction process avoids irregular triangulation patterns that produce:
- Undesirable shading artifacts
- Problematic deformation behavior during character animation
The generative neural network models learn optimal vertex placement strategies by training on high-quality artist-created character models included in the dataset, enabling the AI to automatically generate three-dimensional meshes that meet professional game development and VFX production standards without requiring time-consuming manual retopology workflows.
Texture and Material Inference
The AI system infers realistic skin texture maps and physical material properties from the user's input photograph by computationally analyzing:
- Color distribution patterns
- Specular highlight reflections
- Fine surface detail features visible in the photographic image
Threedium's Photo-to-Avatar Engine extracts texture information from the user's uploaded photograph and projects the captured visual data onto the generated three-dimensional mesh geometry using UV texture mapping coordinates automatically calculated during the reconstruction processing workflow.
This texture projection process preserves:
- Skin tone color variations
- Distinctive facial feature characteristics
- Fine surface texture details from the source photograph
The AI system augments the extracted texture data by:
- Inferring hidden facial regions
- Synthesizing texture information for non-visible areas
- Generating complete 360-degree spherical texture map
The reconstruction system evaluates lighting conditions and generates:
| Map Type | Function |
|---|---|
| Physically-based diffuse albedo maps | Color representation |
| Specular reflection maps | Surface shine properties |
| Normal bump maps | Surface detail texture |
Anatomical Proportion Accuracy
Threedium's AI system preserves accurate anatomical proportions when generating the user's 3D character model from a single photograph, preventing geometric distortions and feature exaggerations that commonly occur when competing reconstruction systems operate with insufficient training data volumes.
Threedium's Photo-to-Avatar Engine learns statistical correlations between facial feature dimensions, inter-feature spacing measurements, and overall cranial proportions through training, applying these learned anatomical constraints during the 3D character generation process to ensure biological realism.
The AI system infers complete full-body anatomical proportions from a facial photograph by identifying learned statistical correlations between:
- Facial structural characteristics
- Corresponding body type categories
- Anatomically realistic body-to-head dimensional ratios
The reconstruction system preserves standard anthropometric facial ratios including:
- Interpupillary distance measurements
- Nose width to mouth width proportional relationships
- Vertical facial thirds divisions
This ensures generated character models conform to biologically realistic anatomical ranges rather than producing caricatured exaggerations or geometrically distorted reconstruction results.
Real-Time Processing Efficiency
Threedium's proprietary AI reconstruction pipeline processes the user's uploaded photograph and generates a complete production-ready 3D character model within seconds, compared to the hours or days of processing time required by traditional multi-view photogrammetry reconstruction methods.
Key efficiency features include:
- Computationally optimized neural network architectures
- Standard cloud-based web infrastructure operation
- Browser-based reconstruction tool interface access
- Offline neural network training phase execution
The reconstruction system delivers real-time processing performance through implementation of:
- Neural network model compression techniques
- Numerical quantization methods
- Architectural optimizations
These optimizations significantly reduce computational resource requirements without compromising:
- Output reconstruction quality
- Geometric accuracy
- Visual fidelity
Users receive their finished production-ready 3D character model within seconds of uploading their source photograph to the platform, facilitating rapid design iteration workflows and enabling immediate visual preview of reconstruction results.
Comparison to Multi-View Reconstruction
Traditional multi-view photogrammetry reconstruction pipelines necessitate capturing dozens of overlapping photographs from precisely calibrated camera positions, creating multiple opportunities for:
- Cumulative error accumulation
- Progressive quality degradation
- Feature correspondence problems
- Geometric holes and mesh distortions
| Traditional Multi-View | Threedium Single-Photo |
|---|---|
| Dozens of photographs required | Single photograph input |
| Controlled studio lighting | Natural lighting conditions |
| Static subject positioning | Casual photograph processing |
| Hours/days processing time | Seconds processing time |
| Complex feature matching | No correspondence problems |
Threedium's proprietary single-photograph reconstruction approach completely eliminates feature correspondence problems, as the AI system reconstructs the complete three-dimensional geometric structure from a single input image, avoiding multi-view registration errors that occur when computationally aligning multiple imperfectly captured or inconsistently lit photographs.
Threedium's AI-based reconstruction approach reduces total end-to-end processing time by approximately 95% compared to traditional multi-view photogrammetry workflows.
Feature Preservation
Threedium's AI system preserves distinctive facial features and individual physical characteristics by algorithmically prioritizing feature-level geometric accuracy throughout the reconstruction process, ensuring unique identifying attributes are maintained in the output model.
The system detects and preserves:
- Facial asymmetries
- Scar tissue
- Moles and birthmarks
- Distinguishing identifying marks
- Wrinkle pattern formations
- Subtle skin texture color variations
Threedium's Photo-to-Avatar Engine detects and algorithmically emphasizes unique aspects of individual facial structure, ensuring these defining physical characteristics transfer accurately and proportionally to the generated 3D character model without averaging or normalization.
The feature preservation system operates across multiple geometric scales:
Macro-level anatomical proportions - Overall face shape - Jaw width measurements
Micro-level surface details - Wrinkle formations - Skin texture variations
Handling Challenging Input Conditions
Threedium's robust computer vision algorithms preserve reconstruction accuracy despite challenging input conditions including:
- Non-uniform lighting distributions
- Partial facial occlusion
- Varied facial expressions
- Non-frontal camera viewing angles
The system successfully handles:
| Challenge Type | Solution Approach |
|---|---|
| Harsh shadows/highlights | Robust deep learning feature extraction |
| Partial occlusion | Statistical anatomical relationship inference |
| Non-neutral expressions | Expression normalization capability |
| Low resolution images | Processing down to 512×512 pixels |
| Compression artifacts | Automatic preprocessing normalization |
Expression normalization capability integrated into the AI system enables accurate 3D reconstruction from input photographs displaying non-neutral facial expressions, generating a 3D character model in a standardized neutral facial pose while preserving the subject's distinctive identifying features and proportions.
The reconstruction system successfully processes input images with resolutions as low as 512×512 pixels while preserving reconstruction quality, and robustly handles:
- JPEG compression artifacts
- Motion blur distortions
- Color balance variations
Users can upload photographs captured with standard smartphone cameras under uncontrolled natural lighting conditions, and the AI system automatically normalizes these input variations during the preprocessing stage before executing the core three-dimensional reconstruction processing pipeline.