





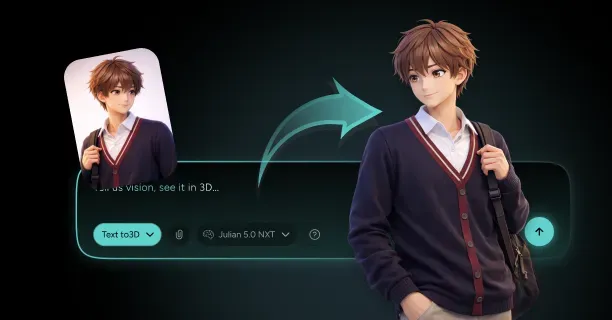
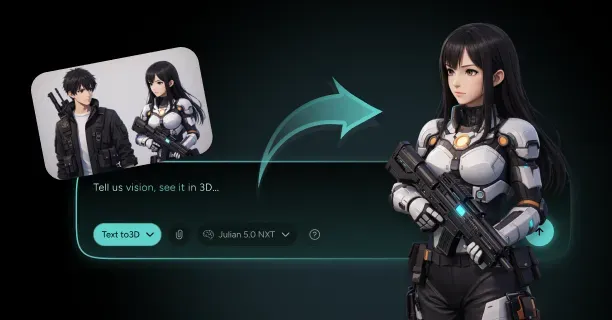
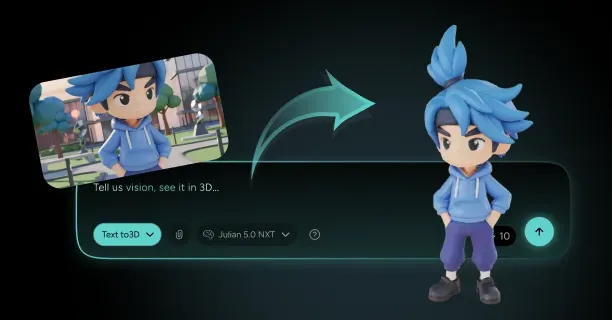
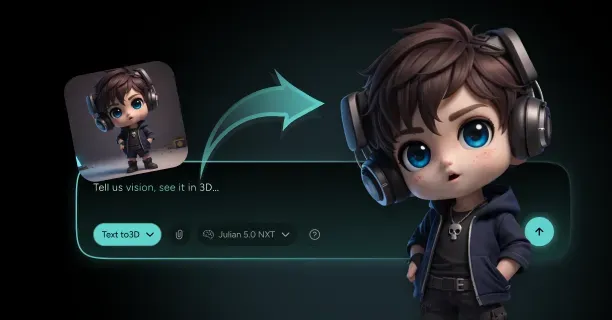







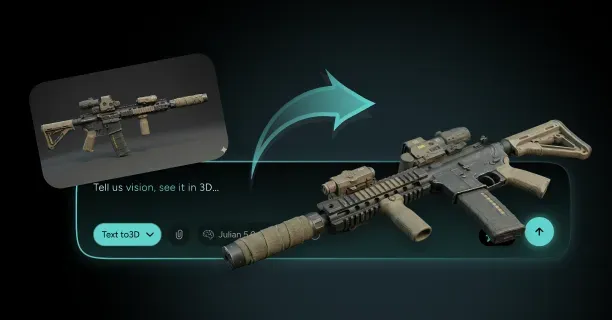










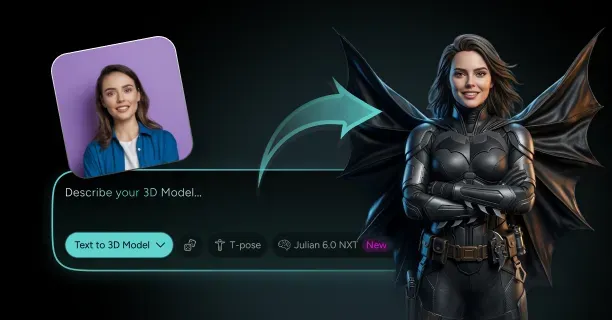


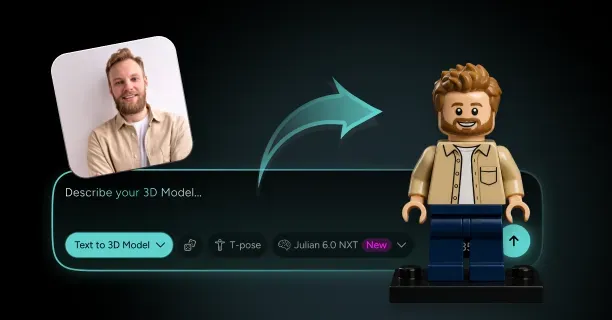
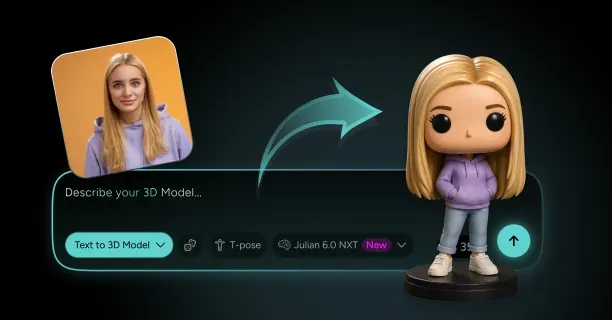
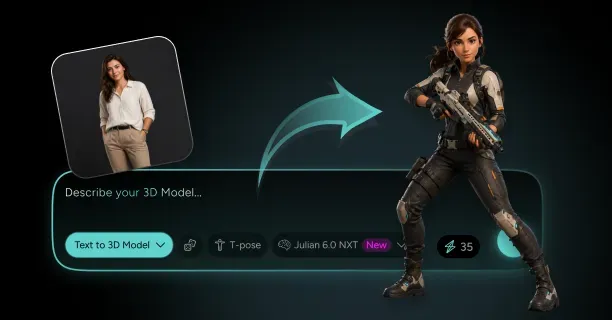
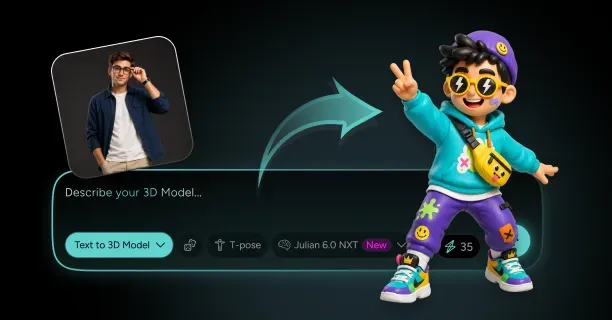

How Do You Create A 3D Model From A Single Image With Threedium?
You create a 3D model from a single image with Threedium by uploading your reference image to our browser-based platform, where our AI processes visual data using computer vision algorithms and automatically synthesizes depth, geometry, textures, and lighting through neural network inference into a production-ready 3D asset. Threedium’s AI-driven reconstruction process eliminates the requirement for manual 3D modeling skills and transforms flat 2D artwork into fully realized three-dimensional models suitable for production use.
Our proprietary Julian NXT technology (Threedium’s specialized artificial intelligence system designed to solve inverse rendering challenges in single-image 3D reconstruction) addresses the inverse rendering problem, the fundamental computer vision challenge involving the decomposition of 2D images into constituent 3D elements:
- Shape data
- Surface material properties (reflectance-based)
- Environmental lighting conditions
Traditional 3D modeling necessitates skilled manual execution of:
- Geometry sculpting
- UV coordinate unwrapping
- Texture painting
- Material configuration
This process consumes between multiple hours and several days of specialized labor. We eliminate these manual steps by using generative neural networks (artificial intelligence systems that create new, original content by learning patterns from training data) trained on massive datasets of 3D objects paired with their 2D representations, enabling the AI to determine spatial relationships, depth cues, and material properties from visual information alone.
Accessing the Platform
You access our web-based interface directly in your browser without:
- Installing specialized software
- Meeting GPU hardware requirements
- Performing technical configuration
Upload a clear, high-resolution reference image of your subject: concept art for anime characters, product photography, or stylized illustration. Threedium’s computer vision algorithms immediately process the image using convolutional neural networks, detecting:
- Geometric edge boundaries through gradient analysis
- Chromatic color gradients
- Lighting-based shadow patterns
- Spatial perspective cues that reveal underlying three-dimensional structure
This analysis happens in real-time as the AI examines every pixel for depth information encoded in occlusion patterns, lighting direction, and surface detail variation, extracting depth information from monocular visual cues.
AI-Powered Geometry Reconstruction
The generative AI component builds upon Neural Radiance Field (NeRF) principles pioneered by Google Research (the research and development division of Google LLC focusing on artificial intelligence and computer vision technologies) in their work on Neural Radiance Fields, which demonstrated how neural networks learn continuous volumetric scene representations from image data.
Traditional NeRF implementations require multiple viewpoints as input data captured from various calibrated camera positions.
Threedium’s single-image reconstruction approach adapts Neural Radiance Field concepts by leveraging prior knowledge embedded in extensive training datasets containing paired 2D-3D examples. The AI system acquired through supervised learning statistical relationships connecting 2D visual features to corresponding 3D geometries across thousands of object categories, enabling probabilistic inference of unseen surfaces and occluded geometry regions.
Threedium’s system employs generative AI models (content-creating artificial intelligence that synthesizes new outputs from learned patterns rather than simply analyzing existing data). The neural networks generate 3D geometry and textures by recognizing patterns learned during training, similar to how diffusion models progressively refine noisy data into coherent images. When users upload reference images, Threedium’s AI system generates entirely new polygon meshes and texture maps specifically tailored to each unique input, rather than retrieving pre-existing 3D models from template libraries. This generative approach ensures each 3D model output matches the user’s unique artistic vision while maintaining topological consistency and mesh quality suitable for real-time rendering engines like Unity and Unreal Engine.
Geometry and Texture Generation Process
The 3D geometry inference process synthesizes through neural network inference a textured polygon mesh by predicting vertex positions and calculating vertex coordinates in Cartesian 3D space. Threedium’s algorithms process silhouette boundaries using edge detection algorithms to establish overall 3D volume and dimensional proportions, then refine surface details by converting shading variations through shading-to-geometry mapping into geometric features like:
- Anatomical muscle definition
- Cloth simulation fabric folds
- Hard-surface mechanical panel lines
Edge detection algorithms detect using gradient analysis sharp intensity-based transitions that are represented as distinct discrete polygon edges rather than continuous interpolated smooth gradients, ensuring through topology optimization the final mesh captures both organic curves and hard-surface elements accurately. The AI simultaneously generates UV coordinate layouts that unwrap the 3D surface into 2D texture space, preparing the model for material application.
Texture mapping and material mapping occur concurrently through parallel neural network branches with geometry generation, as our neural networks predict shape properties and surface appearance properties through multi-task learning architecture. Threedium’s AI system extracts color information directly from the user’s reference image, projecting extracted hues onto corresponding 3D mesh surfaces while computationally accounting for environmental lighting variations that may cause chromatic shift color tinting or value darkening shadowing in the original artwork.
Specular highlights detected in the user’s source image inform roughness parameters and metallic parameters within the physically-based rendering (PBR) material system (a computer graphics approach that renders materials by simulating real-world physical properties of light interaction) ensuring reflective surfaces such as metallic armor plating or specular glossy hair exhibit realistic behavior under physically accurate dynamic lighting conditions. Subsurface scattering properties are computationally derived through material classification for organic skin materials and semi-transparent translucent fabrics, simulating light transmission through semi-transparent materials and adding visual depth to character renders.
Configuration and Parameter Control
Users configure generation parameters through intuitive browser-based controls that adjust AI system behavior without requiring technical knowledge of underlying neural network architectures:
| Control Type | Function | Options |
|---|---|---|
| Style Intensity Slider | Adjust adherence to reference image vs. AI interpretation | Low to High |
| Geometry Complexity | Balance mesh density for different use cases | Hero assets / Game-ready models |
| Material Finish | Specify surface reflectance characteristics | Matte / Satin / Glossy |
Style intensity slider controls enable users to adjust how closely the generated output adheres to the reference image versus introducing AI-driven creative interpretation for missing or occluded details. Geometry complexity settings balance mesh density polygon count between high-fidelity hero assets (high-polygon-count 3D models designed for close-up viewing in offline rendering cinematic rendering) and performance-optimized game-ready models that maintain performance in real-time applications that maintain performance in real-time applications.
Threedium’s browser-based architecture leverages cloud computing infrastructure (on-demand delivery of computing resources over the internet from remote data centers) to execute intensive GPU-intensive neural network computations, enabling users to work from any internet-connected device:
- High-performance desktop workstations
- Portable laptops
- Mobile tablets
All accessing identical server-side processing power. Upload bandwidth automatically adjusts adaptive image compression to balance image quality versus transfer speed, while progressive rendering (a display technique showing low-resolution versions initially then progressively refining detail) displays low-resolution previews within seconds before refining to full detail, providing immediate feedback for improved user experience.
Real-Time Feedback and Preview
Real-time feedback mechanisms display reconstruction progress continuously as the AI system generates geometry layers sequentially following a hierarchical coarse-to-fine approach:
- Initial stage: Base mesh forming, establishing primary overall shape volumes and dimensional ratio proportions
- Mid-frequency detail layer passes: Adding secondary geometric forms such as fabric deformation clothing wrinkles or anatomical detail facial features
- Final stage: High-frequency passes applying fine surface texturing (skin micro-geometry pore detail, textile structure fabric weave patterns, or decorative elements ornamental engravings)
Interactive viewport controls enable users to orbit the emerging 3D model with 360-degree rotation capability, inspecting reconstruction quality from any viewing angle and identifying areas needing adjustment through quality control before finalizing the generated output.
Handling Occluded and Hidden Geometry
Threedium’s AI system handles challenging scenario edge cases that traditionally confound automated reconstruction systems by applying learned statistical priors (statistical knowledge about object categories acquired during neural network training). When the user’s reference image depicts a character in three-quarter view with one arm occluded behind the torso, Threedium’s neural network predicts anatomically plausible limb positioning and realistic limb proportions based on:
- Visible shoulder orientation cues
- Postural body stance analysis
The AI system reconstructs occluded hair sections in hidden regions by analyzing observable visible hair strands for:
- Hair trajectory flow direction
- Hair diameter strand thickness
- Hairstyle characteristic styling patterns
Then generating complementary geometry for hidden sections that maintains visual consistency with visible portions. Partially visible accessories receive fully reconstructed complete 3D forms (combat items like weapons, carried items like bags, or decorative items like jewelry) inferred from observable visible portions and learned patterns of typical object structures based on categorical object type understanding.
Export Formats and Platform Compatibility
Users export completed 3D models in industry-standard file formats compatible with all major creative software platforms and game engines:
| Format | Description | Best Use Case | |---------------------|---------------| | FBX | Autodesk’s proprietary 3D file format | Preserves rigging hierarchies for Unity/Unreal/Blender | | OBJ | Simple geometry format by Wavefront Technologies | Universal cross-platform compatibility | | GLTF | Royalty-free format optimized for web delivery | Three.js and WebGL applications |
FBX (Filmbox) preserves bone structure rigging hierarchies and joint system animation-ready skeletons for immediate import with no conversion needed into Unity, Unreal Engine, or Blender workflows. OBJ format provides universal widely supported geometry compatibility and material mapping texture compatibility across cross-platform 3D software ecosystems, while GLTF (GL Transmission Format) optimizes efficient transmission web delivery for Three.js JavaScript library applications or WebGL browser-based 3D applications.
Each export includes a complete set of PBR texture maps:
- Albedo/diffuse base color map
- Surface detail normal map
- Surface finish roughness map
- Conductor/dielectric metallic map
- Contact shadow ambient occlusion map
These integrate seamlessly with modern rendering pipelines as ready-to-use assets without requiring additional material conversion.
Training Data and AI Capabilities
The extensive training datasets underlying our neural network training are massive in scale and cover wide-ranging diverse object categories, multiple aesthetic artistic styles, and varying difficulty geometric complexities. Training data includes:
- Cultural objects like scanned museum artifacts
- Professionally modeled game characters
- Building component architectural elements
- Commercial item product designs
- Artistic rendering stylized illustrations across:
- Japanese animation anime style
- Western animation cartoon style
- Photorealistic realistic rendering styles
The breadth of training data enables Threedium’s AI to recognize and reconstruct diverse subjects ranging from hard-surface mechanical designs with precise engineering details to anatomical organic characters with complex deformable anatomy. The AI system employs cross-category transfer learning, where vehicle reconstruction insights inform mechanical joint understanding in character armor, while organic form knowledge enhances sculptural design reconstruction in product modeling through domain adaptation knowledge transfer across categories.
Threedium’s computer vision algorithms implement advanced:
- Edge detection (identifying points where brightness changes sharply)
- Pixel-level classification semantic segmentation
- Monocular depth estimation techniques
Convolutional neural network (CNN) layers (deep learning architectures designed for processing grid-like image data) detect multi-scale hierarchical visual features:
- Gradient-based low-level edge orientations
- Geometric pattern mid-level shape primitives
- Object-level high-level semantic concepts like facial recognition “character face” or object part recognition “sword hilt”
Attention mechanisms (neural network components that learn to focus on relevant input parts) focus computational resources selectively on information-rich visually complex regions that contain maximum geometric information, allocating more processing to complex geometry intricate details like hands or high detail facial features while handling efficiently low complexity uniform areas like simple texture plain fabric or minimal detail smooth armor plates.
Post-Processing and Refinement Tools
Users refine AI-generated 3D model outputs through post-processing tools integrated directly within Threedium’s browser interface, eliminating need for external software through all-in-one platform integration:
- Mesh cleanup tools: Automatically merge duplicate vertices, remove topology errors non-manifold geometry (3D mesh topology errors where edges are shared by more than two faces), and optimize polygon flow for animation
- Texture resolution scaling: Automatically adapts output quality to target platform:
- 4K texture maps for offline rendering cinematic renders
- 2K maps for real-time rendering game engines
- 1K maps for performance-optimized mobile applications
- Normal map intensity adjustments: Control how pronounced surface details appear under lighting conditions
Technical Foundation and Neural Architecture
The AI-driven 3D reconstruction represents a modern approach evolution of photogrammetry principles (the science of making measurements and creating 3D models from photographs) where multiple photographs from different viewpoints traditionally triangulate 3D coordinates through geometric parallax analysis, the apparent displacement providing depth calculation information.
Classical photogrammetry requires consistent illumination controlled lighting, known geometry calibrated camera positions, and extensive computational processing to align many viewpoints hundreds of images into coherent 3D data point clouds (sets of data points in 3D space representing external surfaces).
Threedium’s single-image reconstruction approach bypasses traditional photogrammetry requirements by substituting learned statistical priors for the camera-derived geometric constraints that multi-view photogrammetry derives from multiple calibrated camera positions. The neural network computationally infers through probabilistic modeling unobserved viewpoints, synthesizing plausible geometry for occluded regions based on recognized patterns from categorical learned object knowledge acquired during training.
Generative neural networks employ encoder-decoder architecture (a two-stage neural network design where encoders compress and decoders reconstruct) that compress input images into compact high-dimensional vector latent representations (compressed, learned feature encodings capturing essential characteristics in lower-dimensional space), then expand latent codes into full 3D data including vertex position 3D geometry and color map texture data.
The process works as follows:
- Encoder: Analyzes the user’s reference image, extracting high-level concept semantic features such as “spiky hair” hairstyle characteristic, “armored torso” clothing type, or “dynamic pose” body position into numerical vector mathematical representations
- Decoder: Interprets encoded feature vectors, generating 3D coordinate vertex positions, mesh topology polygon connectivity, texture mapping UV coordinates, and color data texture pixel values
Intermediate layers apply learned neural network operation transformations that map 2D visual image features to 3D spatial configurations geometry, refined through supervised learning training on paired datasets millions of image-model pairs consisting of 2D images paired with corresponding 3D models.
Continuous Improvement and Research Integration
Users benefit from continuous AI system improvements as Threedium updates neural network weights regularly based on:
- Growing training data expanding datasets
- Model improvements architectural refinements to the underlying models
Model versions incorporate research-based computer vision advances, including recent developments Gaussian splatting techniques (a 3D scene representation technique modeling scenes as collections of three-dimensional Gaussian distributions used as rendering primitives) that represent 3D scenes as Gaussian collections of 3D Gaussians for efficient real-time rendering. While Threedium’s core technology focuses on polygon mesh generation as the primary output for broad software compatibility, the platform integrates cutting-edge rendering research insights to enhance:
- Visual fidelity output quality
- Mesh structure topology optimization
- Material prediction accuracy
Style Preservation Across Artistic Traditions
Our system handles artistic style preservation by recognizing and maintaining visual characteristics specific to different illustration traditions:
- Anime-style inputs (Japanese animation art style characterized by colorful graphics and distinctive visual conventions): Retain sharp edge cel-shaded boundaries (non-photorealistic rendering making 3D graphics appear flat), stylistic exaggerated proportions, and characteristic simplified geometry forms typical of Japanese animation aesthetic tradition
- Western cartoon references (animation aesthetics from North American and European traditions): Preserve deformation capability squash-and-stretch potential (a fundamental animation principle where objects deform to emphasize motion requiring specific mesh topology), thick edge line bold outlines, and exaggerated proportion stylized anatomy suited to character performance expressive animation
- Realistic photographic inputs: Generate high-resolution detailed surface textures, realistic anatomically accurate proportions, and nuanced subtle material variations appropriate for commercial use product visualization or professional visualization architectural rendering
Production Pipeline Integration
Users integrate Threedium-generated models into existing production pipelines through standard 3D workflow compatibility:
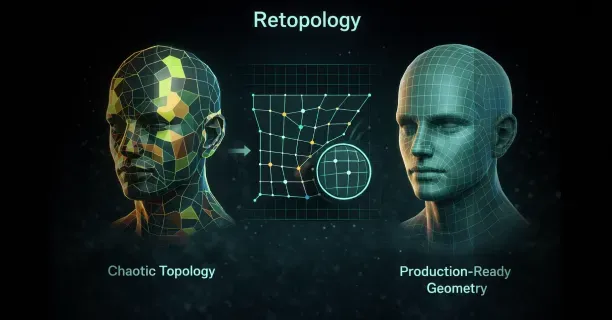
- Blender (free, open-source 3D creation software supporting modeling, rigging, animation, and rendering): Exported meshes import for artist control manual refinement, additional geometry detail sculpting, or topology optimization retopology (the process of reconstructing mesh topology to optimize polygon flow)
- Unity and Unreal Engine projects: Accept exported assets directly with preserved PBR material assignments, ready for scene integration lighting setup, rigging/animation implementation, or collision/dynamics physics configuration
- Web developers: Embed GLTF models into Three.js scenes (a JavaScript library for creating animated 3D graphics in browsers) with simple integration minimal code, using Threedium-generated optimized geometry and web-friendly optimized textures for browser-based responsive rendering in interactive 3D WebGL applications
Cross-platform interoperability ensures Threedium’s AI-generated 3D outputs serve as production-accelerating starting points that augment rather than replace established creative workflows and artist expertise, preserving artist-driven creative control.
Solving the Inverse Rendering Challenge
The inverse rendering problem that our AI solves represents one of computer vision’s fundamental challenges: recovering scene properties from image observations. Forward rendering generates images from known 3D geometry, materials, and lighting through established graphics algorithms. Inverse rendering reverses this process, inferring the 3D scene configuration that would produce observed image pixels under plausible lighting conditions.
The inverse rendering problem is mathematically ill-posed (a mathematical problem lacking unique solution or continuous dependence on input data), admitting multiple non-unique potential solutions because different combinations of 3D geometry, surface materials, and lighting conditions can produce visually equivalent similar 2D image appearances.
Threedium’s neural networks resolve the inverse rendering ambiguity by applying learned statistical priors about:
- Natural object structures
- Material property distributions
- Typical lighting scenarios
Through Bayesian inference probabilistic reasoning, selecting the most plausible 3D interpretation from infinite mathematical possibilities.
Browser-based 3D creation democratizes widespread availability access to professional modeling capabilities previously restricted to skilled specialists with expensive financial barrier software licenses and years of skill barrier technical training. Users create production-ready 3D assets from 2D images (artistic drawing concept sketches, community creation fan art, or commercial image product photography) without learning complex traditional requirement polygon modeling workflows, technical skill UV unwrapping techniques, or artistic skill texture painting methods traditionally required for 3D content creation.
Threedium’s accessibility empowers:
- Individual artists independent creators
- Small teams small studios
- Rapid development prototyping teams
To iterate visual concepts quickly at speeds significantly exceeding traditional modeling, accelerating production cycles creative development. Upload a single input reference image, configure customization generation parameters, and receive a production-ready complete 3D model ready for skeletal setup animation rigging, engine import game integration, or scene use virtual environment placement within minutes time duration through a streamlined three-step process.
What Is Julian NXT And How Does It Improve Image-To-3D Quality And Speed?
Julian NXT is an AI-powered image-to-3D conversion platform that converts single 2D images into high-quality 3D assets by employing a proprietary generative AI architecture that integrates implicit 3D representations (mathematical distance functions) and explicit 3D representations (polygon meshes) while leveraging Gaussian Splatting technology for real-time rendering optimization. Content creators submit one reference image, whether anime artwork, cartoon illustration, or photographic input, and the Julian NXT platform generates a production-ready 3D model equipped with Physically Based Rendering (PBR) materials within minutes, compared to the hours required by traditional 3D modeling workflows.
The Julian NXT hybrid system resolves traditional 3D modeling bottlenecks by analyzing visual features, extracting depth cues, and interpreting semantic content through multiple neural network stages that simultaneously optimize:
- Geometric accuracy (shape precision)
- Texture fidelity (surface detail quality)
- Topological cleanliness (mesh integrity)
Core Architecture and Processing Pipeline
The Julian NXT platform implements a dual-representation strategy that balances and optimizes both geometric precision (accuracy of 3D shape reconstruction) and computational performance (processing speed and rendering efficiency).
Implicit representation methods employ Signed Distance Functions (SDF), a mathematical technique that encodes 3D shapes by computing the shortest distance from any spatial point to the object’s surface boundary, with negative values indicating interior positions, positive values indicating exterior positions, and zero values representing the exact surface.
The Signed Distance Function (SDF) mathematical approach preserves fine surface details including:
- Facial expressions (character emotions)
- Clothing folds (fabric deformation)
- Accessory elements (equipment and ornaments)
These details are frequently lost in explicit polygon mesh representations during initial 3D reconstruction phases. Content creators receive watertight meshes (closed, leak-free 3D geometry) with consistent surface normals (uniform face orientation), automatically eliminating flipped faces (inverted polygons) and non-manifold edges (topological errors) that typically require time-consuming manual correction in traditional photogrammetry-generated outputs.
| Processing Stage | Technology | Output |
|---|---|---|
| Initial Processing | Diffusion-based AI model | Multi-view consistent images |
| Geometry Generation | SDF refinement | Watertight meshes |
| Rendering | Gaussian Splatting | Real-time preview |
| Material Application | PBR analysis | Physically accurate textures |
The initial processing stage executes a diffusion-based AI model that synthesizes multi-view consistent images (coherent perspectives from multiple camera angles) from a single input photograph or artwork submitted by the user. Multi-view consistency (geometric coherence across perspectives) ensures the generated 3D model maintains visual coherence when viewed from all camera angles, preventing geometric distortions and logical contradictions between different perspectives.
The diffusion model synthesizes visual representations showing how the input character or object appears from multiple camera positions, constructing a comprehensive visual understanding (multi-angle appearance data) that guides subsequent 3D geometry generation processes. You provide one reference image, and the system internally produces a complete 360-degree visual representation that serves as the foundation for accurate mesh construction.
Gaussian Splatting Technology for Real-Time Rendering
Gaussian Splatting technology encodes 3D scenes as collections of oriented ellipsoids (three-dimensional Gaussian distributions) that visualize extremely quickly using differentiable rendering processes (gradient-enabled rendering pipelines for neural network optimization).
Differentiable rendering enables gradient propagation (derivative computation) backward through the rendering pipeline, allowing the neural network to learn optimal 3D scene generation parameters by comparing rendered outputs against target images and iteratively refining geometric structures through gradient descent optimization.
Users receive near-instantaneous preview updates while adjusting generation parameters in real-time, as Gaussian Splatting technology visualizes complex 3D scenes at interactive frame rates (30+ frames per second) directly within standard web browsers without requiring specialized GPU hardware or high-end workstations.
Key advantages of Gaussian Splatting technology:
- Real-time quality assessment capabilities during the 3D generation process
- Immediate visual feedback and quality evaluation as the model processes input images
- Progressive quality improvements in the browser viewport (web-based 3D viewer)
- Ability to cancel generation process or adjust parameters if initial reconstruction trajectory fails to match expectations
Traditional 3D reconstruction methods (photogrammetry, multi-view stereo, structured light scanning) necessitate waiting for complete processing before viewing results, resulting in a slow feedback loop (delayed quality assessment) that significantly hinders iterative design refinement and rapid prototyping workflows.
Signed Distance Function Refinement
The refinement stage employs a Signed Distance Function (SDF) that encodes high-fidelity surface geometry (detailed 3D shape representation) with mathematical precision, converting the implicit volumetric representation into exact geometric measurements for accurate mesh generation.
The Signed Distance Function computes exact distance measurements from any spatial coordinate (3D point in space) to the nearest surface point, enabling Julian NXT to reconstruct:
- Smooth, watertight meshes (closed, manifold geometry)
- Elimination of common artifacts including holes (missing geometry)
- Prevention of self-intersections (overlapping surfaces)
- Consistent normals (correct face orientation)
These improvements address issues that frequently plague traditional photogrammetry and multi-view stereo reconstruction techniques. Users obtain clean mesh topology (well-structured polygon geometry) compatible with immediate deployment in:
- Game engines (Unity, Unreal Engine)
- Animation software (Blender, Maya)
- 3D printing workflows
No time-consuming manual cleanup or topology correction is required.
Surface details like facial features, clothing seams, and accessory elements reconstruct with sharp definition rather than the smoothed approximations characteristic of voxel-based approaches. You obtain models that match the visual complexity of your input images, preserving artistic style elements like exaggerated proportions in 3d models shonen or simplified forms in chibi designs.
Physically Based Rendering Material Generation
Julian NXT automatically applies PBR materials to generated geometry, ensuring textures and surface properties behave realistically under varied lighting conditions. PBR methodology models actual light physics, calculating how different materials reflect, absorb, and transmit light based on properties like:
- Metalness
- Roughness
- Albedo color
The model analyzes your input image to extract these material characteristics and applies them as texture maps that remain consistent regardless of rendering conditions, whether bright outdoor lighting or dim interior scenes.
The system separates albedo color (the inherent surface color) from lighting effects (shadows, highlights, reflections) present when your reference image was created. This separation allows the generated 3D model to relight correctly in new scenes rather than baking the original lighting into textures.
You export characters that look natural under the lighting conditions of your game engine or rendering software, maintaining visual consistency with other assets in your project. Exported assets integrate seamlessly into professional 3D environments like Unreal Engine and Unity without requiring material re-authoring.
Speed Enhancements Through Parallel Processing
Speed improvements arise from architectural optimizations that parallelize processing across multiple neural network modules operating simultaneously. The diffusion model generates multi-view images concurrently rather than sequentially, while the SDF refinement process evaluates surface distances using vectorized operations that leverage modern browser WebGL capabilities.
Julian NXT completes full image-to-3D conversions within your browser session, processing complex 3d models josei and detailed objects without server round-trips that introduce latency.
Key speed advantages:
- Complete creative control throughout the generation process
- Real-time parameter adjustment and result viewing
- Browser-based implementation eliminating software installation
- No hardware requirements that traditionally limited 3D content creation to specialists
The system executes entirely within modern web browsers using:
- WebGL for GPU-accelerated rendering
- WebAssembly for compute-intensive neural network operations
This allows you to create production-quality 3D assets from any device with a capable browser.
Quality Improvements Across Multiple Dimensions
Quality enhancements manifest in geometric accuracy, texture fidelity, and topological cleanliness. The hybrid architecture delivers these improvements by leveraging the strengths of both implicit and explicit representations throughout the conversion pipeline.
During initial reconstruction:
- Implicit methods capture fine geometric details and handle complex topology changes
- Explicit mesh generation produces the final output format required by standard 3D software and game engines
You gain the precision of volumetric reconstruction combined with the compatibility of polygon meshes, eliminating the traditional trade-off between accuracy and usability that characterizes older image-to-3D systems.
The generative 3D approach differs fundamentally from traditional 3D scanning or photogrammetry by synthesizing geometry from learned visual patterns rather than triangulating physical measurements.
Julian NXT trains on extensive datasets of 3D models paired with their 2D renderings, learning statistical relationships between image features and underlying 3D structure. This training enables the model to infer plausible 3D geometry even from stylized artwork that lacks photorealistic depth cues, making it particularly effective for converting cartoon and comic art styles into 3D models.
Neural Asset Generation and Parametric Control
Neural asset generation introduces manipulation capabilities that traditional 3D models lack. Julian NXT defines geometry, texture, and material properties through neural network parameters, allowing you to modify high-level attributes like:
- “Make more muscular”
- “Adjust age”
The model propagates these changes consistently across the entire 3D structure. This parametric control operates at a semantic level rather than requiring manual vertex manipulation, enabling rapid iteration through design variations. You explore multiple character concepts by adjusting abstract sliders rather than performing tedious polygon modeling, accelerating the creative development process for game characters and avatars.
Industry-Standard Output Formats
The textured 3D mesh output format ensures compatibility with industry-standard 3D software and game engines. Julian NXT generates UV-mapped meshes with separate texture files for:
- Albedo
- Normal
- Roughness
- Metallic channels
Following PBR conventions, you download assets in formats like:
- FBX
- OBJ
- GLTF
These import directly into Blender, 3d models cinema 4d, and game engines without conversion steps. The mesh topology follows quad-dominant patterns where possible, facilitating subsequent editing and subdivision for higher detail levels when projects require enhanced geometric resolution.
Workflow Efficiency and Iteration Speed
Speed optimizations extend beyond raw processing time to encompass the entire creative workflow. Julian NXT eliminates the multi-stage pipeline of traditional 3D asset creation where geometry modeling, UV unwrapping, texture painting, and material configuration occur separately.
The integrated approach generates all these components simultaneously from your input image, reducing a multi-hour manual process to a single automated conversion. You iterate faster through design concepts, as generating a new variation requires uploading a modified image rather than rebuilding the model from scratch, enabling rapid exploration of character designs for VTuber avatars or metaverse platforms.
Complex Topology Handling
The hybrid architecture’s combination of implicit and explicit representations enables handling of complex topology that challenges pure mesh-based approaches. Characters with intricate hairstyles, flowing garments, or elaborate accessories contain geometric complexity requiring high polygon counts when represented as explicit meshes.
Julian NXT’s implicit SDF representation captures these details efficiently during reconstruction, then converts to optimized polygon meshes that balance:
- Visual fidelity
- Performance constraints
You generate game-ready models maintaining visual quality while meeting polygon budgets for real-time rendering in platforms like Roblox or Fortnite.
Differentiable Rendering Optimization
Differentiable rendering capabilities allow Julian NXT to optimize 3D geometry by comparing rendered views against target images and backpropagating errors through the rendering pipeline. This optimization process refuses the 3D structure to minimize visual differences between the generated model’s appearance and your input image across multiple viewing angles.
The neural network adjusts:
- Vertex positions
- Texture colors
- Material parameters
These adjustments occur iteratively until the rendered output closely matches the reference, ensuring high reconstruction fidelity. You provide a single input image and receive a 3D model that accurately reproduces the image when rendered from the original viewpoint while extrapolating plausible geometry for occluded regions.
Synergistic Quality and Speed Improvements
Quality and speed improvements work synergistically rather than representing a trade-off between competing objectives. The efficient Gaussian Splatting rendering enables rapid iteration through quality-enhancing refinement steps that would be prohibitively slow with traditional polygon rasterization.
The SDF-based geometry definition allows precise surface reconstruction without the computational overhead of extremely high-resolution voxel grids. You achieve both faster processing times and superior output quality compared to previous-generation image-to-3D systems, eliminating the traditional compromise between speed and accuracy that characterized earlier approaches to automated 3D modeling.
Multi-view consistency mechanisms ensure generated 3D models maintain visual coherence when rendered from arbitrary camera angles. The diffusion model learns to produce view-dependent images that correspond to a single underlying 3D structure rather than generating independent images for each viewpoint.
This consistency prevents artifacts where different sides of a character appear to belong to different designs, a common failure mode in naive image-to-3D approaches. You rotate the generated model freely in the preview window and observe consistent appearance across all viewing angles, confirming that the reconstruction captured the intended design accurately.




















